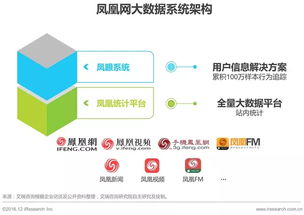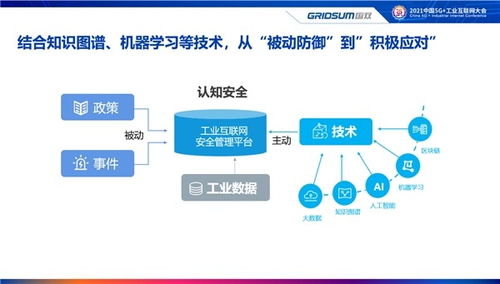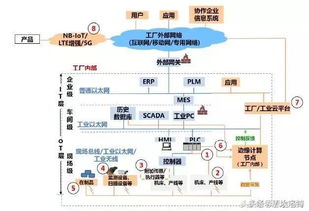
工業互聯網作為數字經濟與實體經濟深度融合的關鍵樞紐,正驅動著制造業的深刻變革。其核心在于通過數據這一新型生產要素,連接人、機、物、系統,實現全要素、全產業鏈、全價值鏈的全面鏈接與優化。本文將通過一張核心架構框圖,帶您層層剖析工業互聯網數據服務的本質、構成與價值實現路徑。
一、總體架構:三層模型勾勒數據流轉全景
工業互聯網數據服務的典型架構可分為三層:
- 邊緣層(數據采集與邊緣智能):這是數據的源頭。通過智能傳感器、物聯網(IoT)網關、工業協議解析等手段,實時采集設備運行參數、生產工藝數據、環境狀態等海量、多源的原始數據。在此層,邊緣計算節點可進行初步的數據清洗、濾波和實時分析,實現毫秒級的本地閉環控制(如預測性維護預警),并降低上行帶寬壓力。
- 平臺層(數據匯聚、管理與分析核心):這是工業互聯網的“大腦”。工業互聯網平臺(如PaaS平臺)在此層匯聚來自各邊緣節點的數據,進行統一的數據集成、存儲、治理與建模。它提供大數據分析、機器學習模型訓練、數字孿生構建等核心能力,將原始數據轉化為可用的信息與知識。平臺層也提供豐富的微服務組件和開發工具,支撐上層應用的快速構建。
- 應用層(數據價值實現與場景賦能):這是價值呈現的舞臺。基于平臺層的能力,開發出面向特定行業和場景的SaaS應用,例如:
- 設備健康管理:基于振動、溫度等數據分析,實現預測性維護,減少非計劃停機。
- 生產流程優化:通過分析MES、SCADA數據,優化排產計劃,提升產能與資源利用率。
- 供應鏈協同:打通上下游數據,實現需求精準預測、庫存智能管理和物流可視追蹤。
- 能源管理與碳足跡追蹤:監控全廠能耗,優化能源調度,實現綠色低碳生產。
二、數據服務的核心要素:從“采、存、算”到“管、用、服”
框圖的核心揭示了數據服務的關鍵活動鏈:
- 采:解決異構設備、多樣協議的互聯互通與數據實時可靠采集。
- 存:針對時序數據、關系數據、非結構化數據(如圖像、視頻)的混合存儲需求,采用時序數據庫、數據湖等技術構建低成本、高可用的數據底座。
- 算:融合邊緣計算(低延時)、云計算(高彈性)與高性能計算(復雜仿真),提供算力支撐。
- 管:建立數據標準、質量評估、安全分級與生命周期管理體系,確保數據可信、可用。
- 用:通過數據分析、可視化、AI模型,將數據轉化為生產洞察、決策支持和自動化指令。
- 服:形成可訂閱、可配置的數據產品與服務,如數據API、分析報告、優化解決方案等,實現商業價值閉環。
三、關鍵支撐:安全與標準貫穿始終
在框圖的外圍,安全與標準是兩大基石。
- 安全:需構建覆蓋終端、網絡、平臺、數據的縱深防御體系,特別是保障工控系統的安全性,防范數據泄露、網絡攻擊和生產中斷風險。
- 標準:包括互聯互通接口標準、數據語義模型標準(如資產管理殼)、行業應用標準等,是打破“數據孤島”、實現跨系統跨企業協同的前提。
四、價值透視:數據驅動制造新范式
透過這張框圖,工業互聯網數據服務的終極價值清晰顯現:
- 提升效率:通過精準感知與優化決策,降本增效。
- 創新模式:催生服務型制造(如按使用付費)、個性化定制等新業態。
- 增強韌性:實現供應鏈透明化與彈性調度,提升抗風險能力。
- 促進可持續發展:通過精細化能源與資源管理,助力“雙碳”目標達成。
****
工業互聯網數據服務并非簡單的IT系統疊加,而是一個以數據流驅動業務流、價值流的復雜系統工程。這張干貨框圖如同一張“導航圖”,揭示了從物理世界感知到數字空間分析,再回到物理世界優化的完整閉環。理解這一架構,有助于企業避開碎片化建設陷阱,系統性地規劃自身數字化轉型路徑,真正釋放工業數據的巨大潛能。